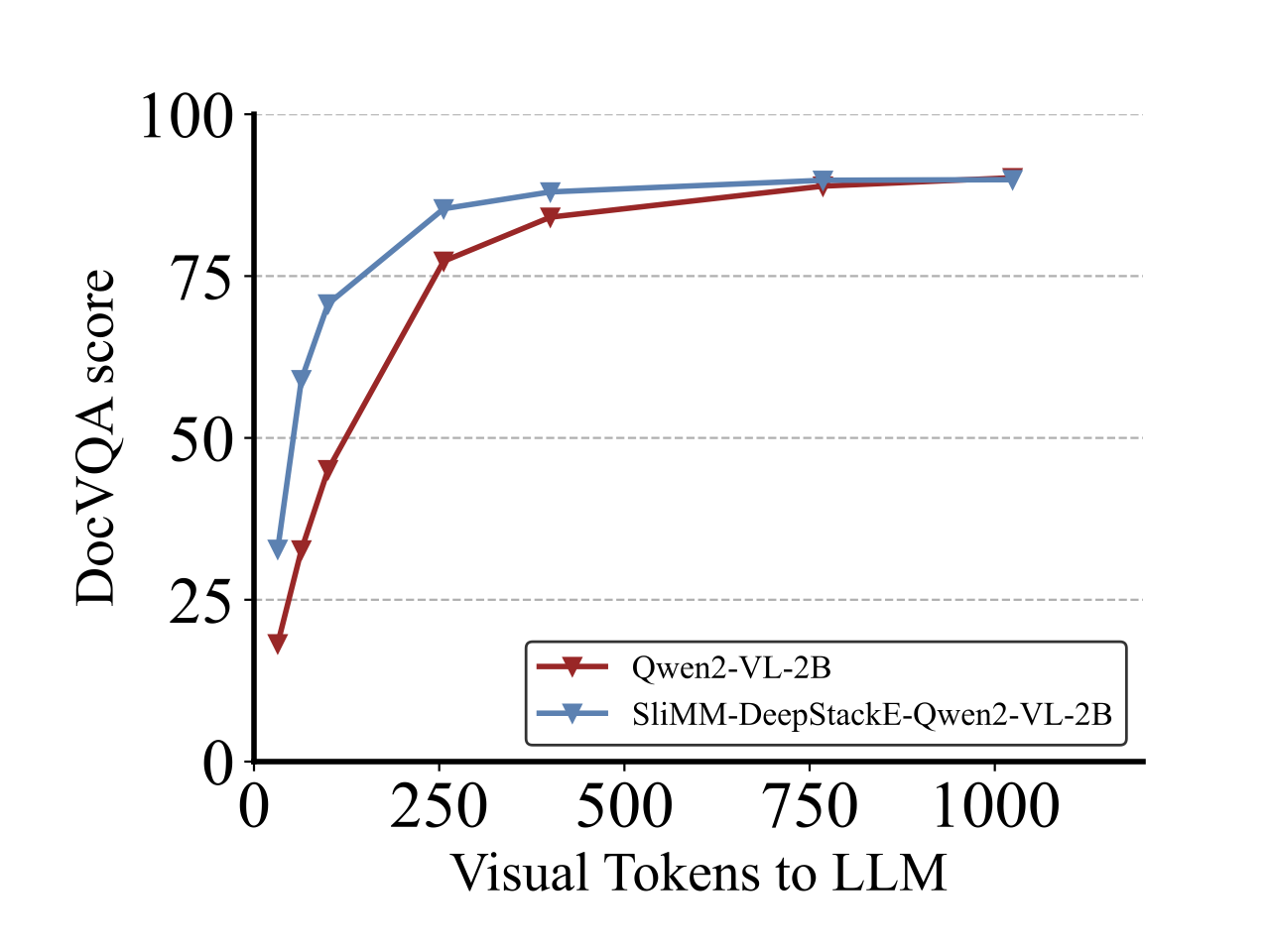
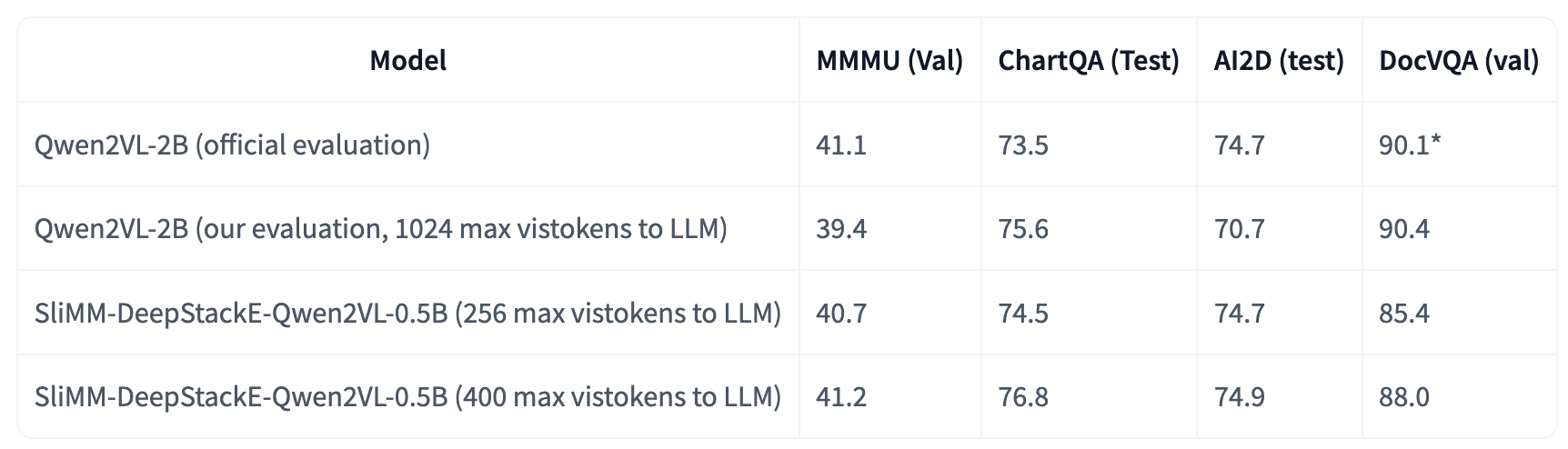
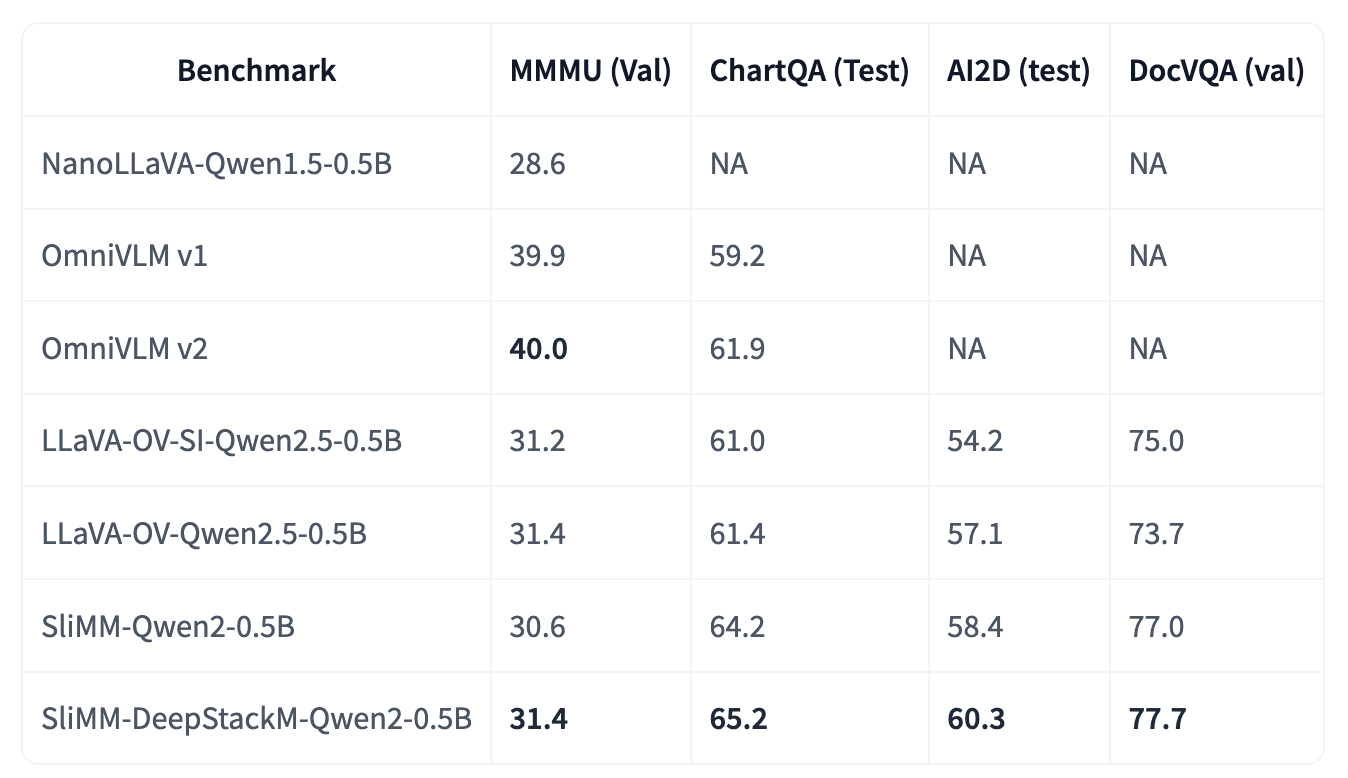

Most large multimodal models (LMMs) are implemented by feeding visual tokens as a sequence into the first layer of a large language model (LLM). The resulting architecture is simple but significantly increases computation and memory costs, as it has to handle a large number of additional tokens in its input layer. This paper presents a new architecture DeepStack for LMMs. Considering N layers in the language and vision transformer of LMMs, we stack the visual tokens into N groups and feed each group to its aligned transformer layer from bottom to top. Surprisingly, this simple method greatly enhances the power of LMMs to model interactions among visual tokens across layers but with minimal additional cost. We apply DeepStack to both language and vision transformer in LMMs, and validate the effectiveness of DeepStack LMMs with extensive empirical results. Using the same context length, our DeepStack 7B and 13B parameters surpass their counterparts by 2.7 and 2.9 on average across 9 benchmarks, respectively. Using only one-fifth of the context length, DeepStack rivals closely to the counterparts that use the full context length. These gains are particularly pronounced on high-resolution tasks, e.g., 4.2, 11.0, 4.0 improvements on TextVQA, DocVQA, and InfoVQA compared to LLaVA-1.5-7B, respectively. We further apply DeepStack to vision transformer layers, which brings us a similar amount of improvements, 3.8 on average compared with LLaVA-1.5-7B.
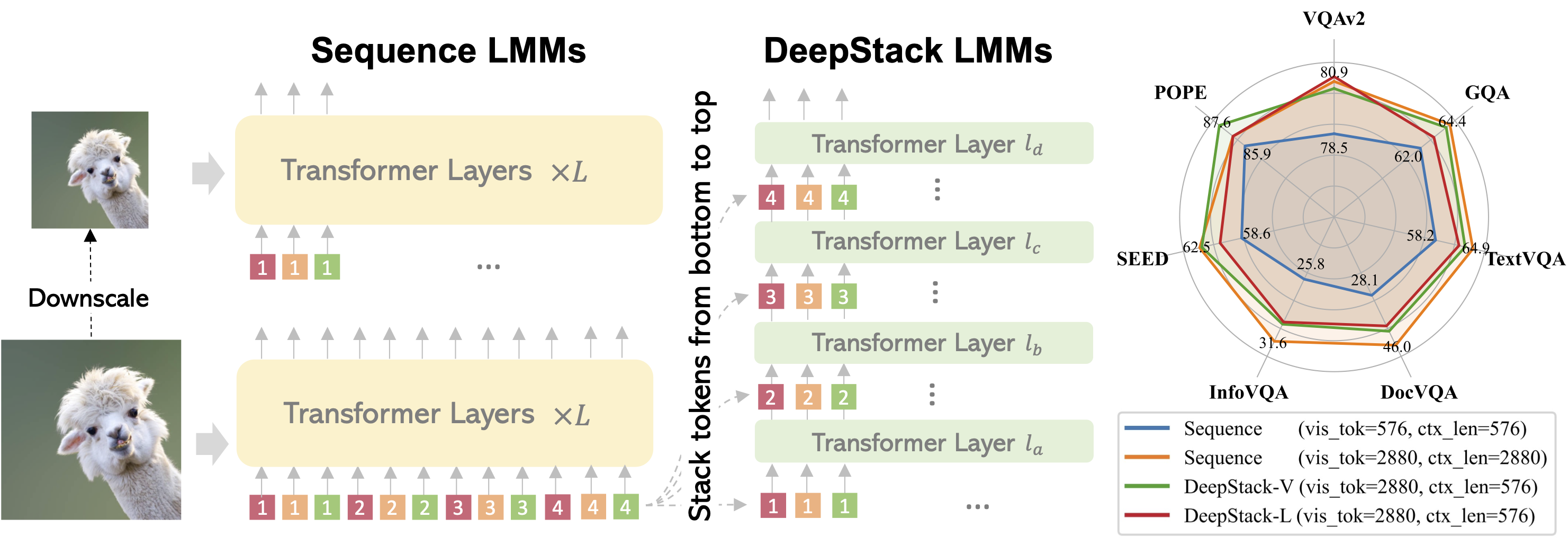
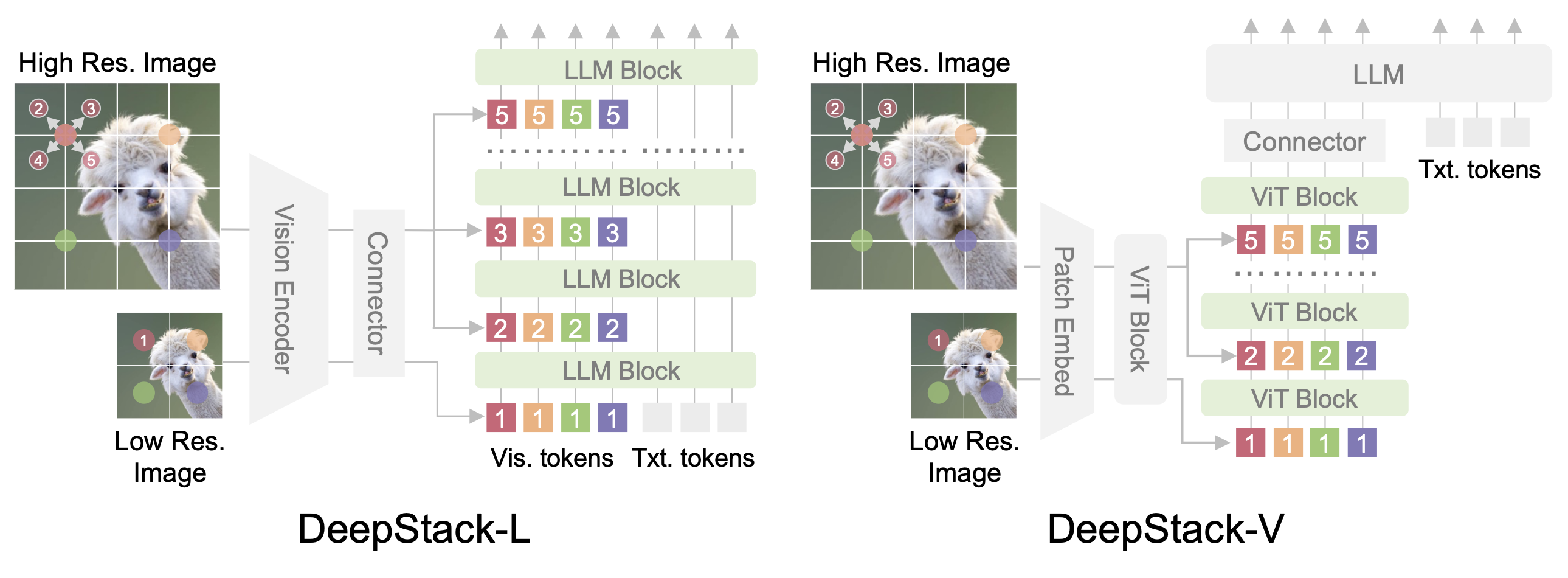
The framework of DeepStack is quite simple: the main innovation lies in the DeepStack strategy that infuses visual tokens into different layers. Left: DeepStack for LLMs. Given an input image, we feed the tokens extracted from the low-resolution version to the input layer of LLM. Considering the 2D nature of images, we extra the neighbors from the high-resolution version and reorganize them into DeepStack, which are then fed to the consequent layers in LLMs. Right: DeepStack for ViTs. We apply similar sampling strategy but feed the visual tokens into the ViT layers of vision encoder.
@inproceedings{meng2024deepstack,
title={DeepStack: Deeply Stacking Visual Tokens is Surprisingly Simple and Effective for LMMs},
author={Meng, Lingchen and Yang, Jianwei and Tian, Rui and Dai, Xiyang and Wu, Zuxuan and Gao, Jianfeng and Jiang, Yu-Gang},
booktitle={NeurIPS},
year={2024}
}
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. We thank the LLaMA team for giving us access to their models, and open-source projects, including Alpaca and Vicuna.
Usage and License Notices: The data, code and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of CLIP, LLaMA, Vicuna and GPT-4. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.
Related Links: [CLIP] [LLaVA] [Instruction Tuning with GPT-4]